Data Lake vs Data Warehouse: Choosing the Right Data Storage
For organisations looking to maximise data power, choosing between a Data Lake vs a Data Warehouse is crucial in the ever-changing data management landscape.

28
Mar
Data Lake vs Data Warehouse: Choosing the Right Data Storage
Table of Contents
For organisations looking to maximise data power, choosing between a Data Lake vs a Data Warehouse is crucial in the ever-changing data management landscape. While both storage solutions manage data, their design, functionality, and best use cases differ.
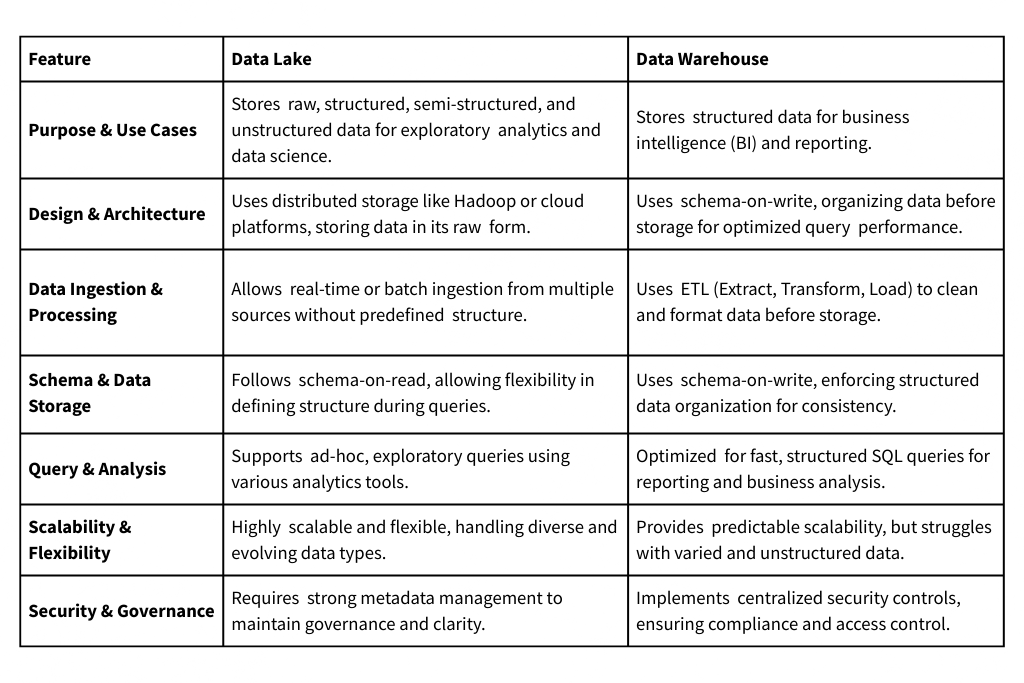
Data Lake vs Data Warehouse are regularly used in data storage conversations, but recognising their differences is vital. A Data Lake stores raw, unstructured, semi-structured, and organised data at scale. Organisations may keep data in its natural format without schemas since it's flexible. Instead, a Data Warehouse is an organised storehouse for querying and analysis. It combines data from several sources and organises it into schemas for consistency and fast retrieval.
As we compare Data Lakes vs Data Warehouses, we must understand their purposes, use cases, architecture, and other key features. Let us guide you through the data storage solutions complex landscape to help you choose the right one for your business.
Read More: Data Science vs Data Analytics
Purpose and Applications
Data Lake
Data Lake is a multipurpose reservoir, especially when the data analysis aim is unclear. It handles organised, semi-structured, and unstructured data in its raw form. This unrestrictive environment makes Data Lakes appropriate for exploratory analytics, data science initiatives, and circumstances where data structure and purpose change throughout analysis.
Data Lakes are flexible and can handle social media feeds, IoT data, and transactional information, making them a good choice for organisations with many data sources.
The Data Warehouse
In contrast, the Data Warehouse is designed for organised data processing, reporting, and business intelligence. It integrates data from numerous sources, cleanses it, formats it, and organises it according to schemas. This rigorous method maintains data quality and consistency, laying the groundwork for analytical procedures.
Data warehouses are popular for business intelligence applications because they quickly and efficiently answer complicated SQL queries. An organised Data Warehouse is a trusted asset for organisations that value data quality and efficient analysis.
Design and Architecture
Data Lake
Data Lakes uses distributed architectures like Apache Hadoop or cloud storage. Data Lakes hold data raw and apply the schema dynamically when querying. This approach gives consumers unmatched freedom to analyse and arrange data for their analytical purposes.
Due to its distributed nature, Data Lake architecture can scale to manage massive volumes of data across various storage systems. Schema-on-read's flexibility can cause schema ambiguity, needing careful metadata and documentation management to clarify.
Architecture of Data Warehouse
In contrast, data warehouses employ star or snowflake schemas and greater organisation. Data is cleaned, converted, and organised into specified schemas before being put into the warehouse in this schema-on-write technique. This upfront architecture optimises query efficiency, speeding up insight retrieval.
The hierarchical design of Data Warehouses makes data management predictable and controlled. Compared to the Data Lake design, it may struggle to handle varied data kinds and adapt to changing data needs.
Understanding the architectural differences between Data Lakes vs Data Warehouses helps explain data input, processing, and storage.
Data Ingestion and Processing
Data Lake
Data Lakes are ideal for real-time or batch data input from many sources. Data Lakes can store raw, unfiltered data from IoT devices, social media, and transactional systems. This adaptability is essential when data format and structure are unknown.
Data Lakes allow users to modify and alter data for analysis. Exploratory data analysts benefit from this capacity to change and experiment with data on the go.
The Data Warehouse
For data input and processing, data warehouses employ ETL. This entails taking data from diverse sources, standardising it, and feeding it into the warehouse using schemas. This organised procedure assures data consistency and integrity upfront, which is crucial for data-driven organisations.
ETL methods offer a solid basis for clean and organised warehouse data, however they may delay data availability compared to Data Lakes. This makes Data Warehouses ideal for situations when data quality and completeness trump immediacy.
As we learn about data input and processing, the difference between a Data Lake and vs Data Warehouse goes beyond storage.
Schema and Data Storage
Data Lake
Data Lakes store data in its natural format, revolutionising data storage. Data Lake data preserves its structure and granularity without schemas. The schema-on-read technique lets users dynamically understand and apply schemas when querying, giving them unmatched flexibility in managing various and developing data types.
Data Lakes are appropriate for fluid data structures and changing analytical requirements since they have no schema. This flexibility lets organisations retain massive volumes of raw, unfiltered data without considerable organising.
The Data Warehouse
Data, In contrast, warehouses follow a schema. Before intake, data is formatted and normalised to ensure warehouse organisation. Business intelligence and reporting applications benefit from this structured approach's improved query efficiency and faster insights retrieval.
The predetermined schema improves data consistency and predictability, but it might make handling varied data types or data structure changes difficult. Data Warehouses are useful for analytical operations that require a well-defined framework.
As we discuss data storage and schema, it becomes clear that choosing between a Data Lake vs a Data Warehouse requires a delicate balance between flexibility and structure.
Query and Analysis
Data Lake
Data Lakes provides ad-hoc querying and exploratory analysis. The schema-on-read technique lets analysts and data scientists explore raw, unstructured data to find insights from multiple sources. A variety of analytics tools and languages are supported, enabling data analysis and experimentation.
Data Lakes' ad-hoc querying makes them useful for unstructured data or deep data analysis. Data Lakes excels at extracting useful insights from large and diverse information with creativity and agility.
The Data Warehouse
Structured query execution and analytical processing are data warehouse strengths. Complex SQL queries run fast and scalable in Data Warehouses for business intelligence and reporting. Data in the warehouse is arranged for efficient processing and retrieval of curated datasets.
Data Warehouses make structured data analysis fast and reliable for business analysts and decision-makers. They are useful for consistent and predictable situations because to their preset schema and optimised query processing.
As we explore query and analysis, we realise that a Data Lake or Data Warehouse depends on the analytical activities at hand.
Scalability and Flexibility
Data Lake
Data Lakes can scale to huge data volumes across dispersed storage systems. Scalability is especially useful when data quantities are uncertain or rise rapidly. Data Lakes' distributed design lets organisations extend their storage infrastructure to meet big data's growing demands.
Data Lakes provide unmatched data storage and processing flexibility beyond scalability. Organisations with different data types, shifting analytical workloads, and flexible data requirements need this agility.
The Data Warehouse
Data Warehouses are scalable, but they may need more technology or infrastructure to handle expanding data volumes. Warehouses' structure makes data management predictable, but current data's burstiness and diversity may restrict them.
Well-defined structure and predictable scalability make data warehouses ideal. Data Lakes' scalability and flexibility may be better for organisations managing changing data environments.
As we examine scalability and flexibility, the choice between a Data Lake vs a Data Warehouse goes beyond performance.
Security and Governance
Data Lake
Data Lake security and governance demand a holistic strategy. Protecting sensitive lake data requires access controls, encryption, and audits. Fine-grained access controls let organisations restrict dataset access to authorised individuals, protecting sensitive data.
Data lineage and governance need metadata management. Metadata helps with data context and compliance by giving a clear record of data operations. Organisations may preserve data integrity and prevent unauthorised access by encrypting data at rest and in transit.
The Data Warehouse
To protect sensitive data, Data Warehouses prioritise security and governance. Fine-grained access restrictions and role-based permissions restrict warehouse data manipulation to authorised users. Protection against security breaches is enhanced by rest and transit encryption.
Centralised information and lineage tracking strengthen governance. Data access and alterations can be audited to ensure regulatory compliance. Organisations handling sensitive and regulated data need data warehouses to safeguard data assets.
Read More:- Battle of Power BI and Tableau
Conclusion
Data management is dynamic, therefore choosing between a Data Lake and a Data Warehouse depends on your organization's needs and subtleties. Each method has pros and cons for different use cases and data types.
Data Lakes' schema-on-read flexibility makes them ideal for exploratory analytics, different data kinds, and unexpected expansion. However, Data Warehouses' organised approach and optimised query efficiency make them ideal for business intelligence and reporting applications that require data consistency.
Modern data environments are complicated, so organisations must recognise that the best answer may not be a one-size-fits-all strategy. Decision-making requires careful consideration of data attributes, analytical use cases, performance, scalability, adaptability, security, governance, and cost.






Anshul Goyal
Group BDM at B M Infotrade | 11+ years Experience | Business Consultancy | Providing solutions in Cyber Security, Data Analytics, Cloud Computing, Digitization, Data and AI | IT Sales Leader